
تشهد صناعة الرعاية الصحية تحولاً بفضل تقنيات الذكاء الاصطناعي؛ إذ تشير التوقعات إلى نمو سوق تقنيات الذكاء الاصطناعي في قطاع الرعاية الصحية بنسبة تصل إلى 1700% بحلول عام 2030 مقارنةً بما كانت عليه في عام 2021.
هذا النمو السريع يعكس التزايد الكبير في استخدام الذكاء الاصطناعي في صناعة الرعاية الصحية بوتيرة غير مسبوقة. حالياً، تعتمد نحو خُمس المنظمات الصحية نماذج الذكاء الاصطناعي في حلولها الصحية؛ مما يبرز الدور الحيوي والمتنامي لهذه التقنية في تحسين وتطوير الرعاية الصحية على مستوى العالم.
ففي وقت قصير، أصبحت تقنيات الذكاء الاصطناعي ذات أهمية متزايدة للأطباء وغيرهم من العاملين في مجال الصحة، وساعدهم ذلك على اتخاذ قرارات أفضل بشأن التشخيص والعلاج، والتنبؤ بتطور الأمراض، واكتشاف علاجات جديدة. كما أدى دوراً في الوقاية من الأمراض والحد من سرعة انتشار الأوبئة، من خلال التعرف على الأشخاص المعرضين لخطر الإصابة بالمرض وتوجيه الأطباء لاتخاذ القرارات الوقائية المناسبة.

تطبيقات واعدة:
هناك العديد من التطبيقات المحتملة للذكاء الاصطناعي في مجال الصحة والرعاية الطبية، ومن بين تلك التطبيقات:
1- تشخيص الأمراض والوقاية منها: البيانات الضخمة لها تأثير كبير في تشخيص الأمراض والوقاية منها. ومن خلال تحليل مجموعات كبيرة من بيانات سجلات المرضى، يمكن لمتخصصي الرعاية الصحية تحديد الأنماط وعوامل الخطر التي قد يتم التغاضي عنها من خلال طرق التشخيص التقليدية. على سبيل المثال، تم استخدام البيانات الضخمة لتحديد العلامات الجينية التي تشير إلى ارتفاع خطر الإصابة بسرطان الثدي؛ مما يمكن الأطباء من تطوير استراتيجيات فحص ووقاية أكثر استهدافاً للمرض. ومع الاستمرار في جمع وتحليل المزيد من البيانات، يمكن أن يساعد الذكاء الاصطناعي على تحديد الأفراد المعرضين للخطر الشديد؛ مما يتيح التدخلات المستهدفة والتدابير الوقائية للحد من حدوث المرض.
2- تطوير الأدوية: تُحدث البيانات الضخمة أيضاً ثورة في تطوير الأدوية؛ إذ تستخدم شركات الأدوية خوارزميات التعلم الآلي لتحليل كميات هائلة من البيانات وتحديد الأهداف الدوائية المحتملة بسرعة ودقة أكبر من أي وقت مضى. ولا يؤدي هذا إلى تسريع عملية تطوير الأدوية فحسب، بل يعمل أيضاً على تحسين فرص نجاح الأدوية الجديدة. علاوة على ذلك، يمكن أن يساعد الذكاء الاصطناعي على تحديد الآثار الجانبية والتفاعلات المحتملة، وتحسين سلامة الأدوية وتقليل مخاطر التفاعلات الضارة.
3- التنبؤ بتطور المرض: يمكن استخدام الذكاء الاصطناعي لتحليل البيانات الواردة من المرضى الذين يعانون من أمراض مزمنة، مثل: مرض السكري أو أمراض القلب، للتنبؤ بكيفية تطور حالتهم. يمكن أن تساعد هذه المعلومات الأطباء على تصميم خطط رعاية شخصية لتلبية احتياجات كل مريض. على سبيل المثال، تستخدم الوحدة الصحية التابعة لشركة Google DeepMind خوارزميات التعلم الآلي للتنبؤ بالفشل الكلوي قبل ما يصل إلى 48 ساعة مقدماً؛ مما يتيح التدخل المبكر وتحسين نتائج المرضى. ومن خلال التنبؤ بتطور المرض، يمكن لمتخصصي الرعاية الصحية اتخاذ تدابير استباقية لمنع المضاعفات وتحسين نتائج المرضى.
4- خطط العلاج الشخصية: يساعد استخدام الذكاء الاصطناعي على تطوير الخطط العلاجية للمرضى؛ إذ يتم تصميم العلاجات لتناسب المرضى الأفراد بناءً على ملفاتهم الجينية وتاريخهم الطبي ونمط حياتهم. ومن خلال تحليل بيانات المرضى، يمكن لمتخصصي الرعاية الصحية تحديد الأنماط والارتباطات التي يمكن أن تفيد خطط العلاج الشخصية؛ وهو ما يمكن أن يؤدي إلى علاجات أكثر فعالية وتحسين نتائج المرضى.
كما يمكن أن يساعد الذكاء الاصطناعي أيضاً على تحديد المستجيبين وغير المستجيبين لعلاجات محددة، مما يمكّن المتخصصين في الرعاية الصحية من اتخاذ قرارات أكثر استنارة بشأن خيارات العلاج. على سبيل المثال، يمكن للخوارزميات التي تعمل بالذكاء الاصطناعي تحليل البيانات لتحديد المرضى الذين من المرجح أن يستجيبوا لعلاجات محددة للسرطان، وتحسين نتائج العلاج وتقليل مخاطر ردود الفعل السلبية.
5- الجراحة بمساعدة الروبوت: يتم استخدام الذكاء الاصطناعي لتحسين النتائج الجراحية، فيمكن للجراحة بمساعدة الروبوت، والمدعومة بخوارزميات الذكاء الاصطناعي، تحسين الدقة، وتقليل خطر حدوث المضاعفات وتحسين نتائج المرضى. كما يمكن للروبوتات التي تعمل بالذكاء الاصطناعي أيضاً مساعدة الجراحين أثناء العمليات المعقدة؛ مما يسمح بحركات مرنة ودقيقة. ويمكن لروبوتات الدردشة المدعومة بالذكاء الاصطناعي مساعدة المرضى الذين يعانون من مشكلات في الصحة العقلية من خلال توفير إرشادات على مدار الساعة طوال أيام الأسبوع؛ مما يقلل الحاجة إلى جلسات العلاج الشخصية.
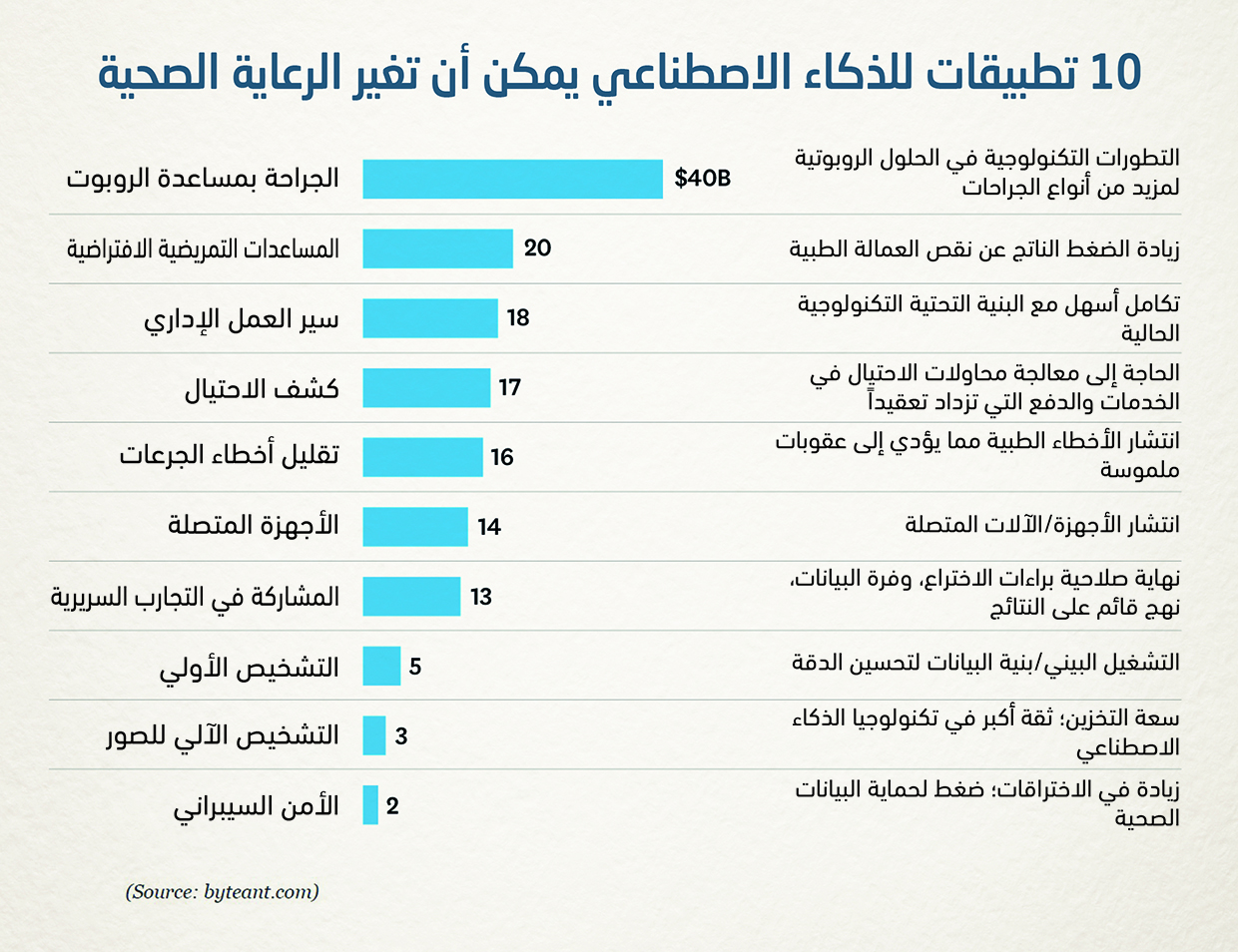
يمثل الشكل التالي القيمة السنوية لتطبيقات الذكاء الاصطناعي المستخدمة في قطاعات الرعاية الصحية بحلول عام 2026. ويتضمن ذلك الجراحة بمساعدة الروبوتات 40 مليار دولار، ومساعدي التمريض الافتراضيين 20 مليار دولار، وسير العمل الإداري 18 مليار دولار، واكتشاف الاحتيال 17 مليار دولار، وتقليل أخطاء الجرعات 17 مليار دولار، والأجهزة المتصلة 14 مليار دولار، والمشاركة في التجارب السريرية 13 مليار دولار، والتشخيص الأولي 5 مليارات دولار، والتشخيص الآلي للصور 3 مليارات دولار، والأمن السيبراني 2 مليار دولار.
ميزات عديدة:
تُقدم تقنيات الذكاء الاصطناعي مجموعة واسعة من الفوائد التي تُحدث ثورة في قطاع الرعاية الصحية؛ مما يُسهم في تحسين جودة الرعاية المقدمة للمرضى وتقليل التكاليف.
1- تحسين الدقة في التشخيص: إحدى الفوائد الأساسية للذكاء الاصطناعي في مجال الرعاية الصحية هي قدرته على تحسين دقة التشخيص وخطط العلاج؛ إذ يمكن لنماذج الذكاء الاصطناعي تحليل كميات هائلة من البيانات الطبية، بما في ذلك الصور الطبية مثل: الأشعة السينية والتصوير بالرنين المغناطيسي، والتاريخ المرضي للمرضى، والتقارير الطبية.
وبفضل قدراتها على تحديد الأنماط والعلاقات المتبادلة التي قد لا تكون واضحة للأطباء البشريين، تُساعد هذه النماذج الأطباء على تشخيص الأمراض بدقة أكبر وسرعة فائقة. وتُمكنهم أيضاً من تحديد المخاطر الصحية المحتملة للمريض وتوجيهه نحو اتخاذ القرارات الوقائية المناسبة. بالإضافة إلى ذلك، يمكن أن يساعد الذكاء الاصطناعي على تقليل مخاطر الأخطاء الطبية، والتي يمكن أن تحدث عندما يخطئ الأطباء البشريون في تفسير المعلومات المهمة أو يتجاهلونها.
2- اتخاذ قرارات أسرع: الوقت عنصر أساسي في الرعاية الصحية، والتأخير في التشخيص والعلاج يمكن أن تكون له عواقب وخيمة، ويمكن أن يساعد الذكاء الاصطناعي على تسريع عملية اتخاذ القرار من خلال تزويد الأطباء بمعلومات دقيقة وفي الوقت المناسب، ففي حالات الطوارئ، يكون الوقت عاملاً حاسماً في إنقاذ حياة المرضى. كما تُمكن تقنيات الذكاء الاصطناعي الأطباء من اتخاذ القرارات العلاجية بسرعة أكبر بفضل قدرتها على تحليل البيانات ومعالجة المعلومات بسرعة فائقة. وتُساعد هذه التقنيات أيضاً على تحسين فعالية العلاج من خلال توفير المعلومات الدقيقة والضرورية في الوقت المناسب.
تستثمر بعض الشركات الكبرى في مجال الذكاء الاصطناعي، مثل: NVIDIA وAmazon وMicrosoft وGoogle وIBM. وتستخدم منصة Health Watson التابعة لشركة IBM الذكاء الاصطناعي لمساعدة الأطباء على اتخاذ قرارات أكثر وعياً وتحسين النتائج للمرضى. كما تعمل شركة Health DeepMind التابعة لجوجل على استخدام الذكاء الاصطناعي للمساعدة على تشخيص وعلاج الأمراض مثل: السرطان وأمراض القلب.
3- تقليل التكاليف: تُسهم تقنيات الذكاء الاصطناعي في تقليل تكاليف الرعاية الصحية من خلال أتمتة المهام الروتينية مثل: إدخال البيانات وتنظيم السجلات الطبية. تُمكن هذه التقنيات أيضاً من تحسين كفاءة التجارب السريرية؛ مما يُساعد على اختصار الوقت اللازم لتطوير الأدوية وتقليل التكاليف المرتبطة بذلك وتخصيص الموارد بشكل أكثر فعالية. بالإضافة إلى ذلك، يمكن أن تساعد نماذج الذكاء الاصطناعي على تحديد الإجراءات والعلاجات غير الضرورية؛ مما قد يساعد على تقليل الإنفاق على الرعاية الصحية.
تحديات ومخاطر:
إلى جانب الفرص؛ يُعد استخدام الذكاء الاصطناعي في مجال الصحة أمراً محفوفاً بالكثير من التحديات، وأبرزها:
1- الغموض: أحد التحديات هو أن نتائج نماذج الذكاء الاصطناعي غالباً ما تكون غامضة للأطباء؛ مما يجعل من الصعب فهم كيفية وصولها إلى تلك النتائج، وهو ما يُعد تحدياً عندما يتعلق الأمر بتشخيص المرض؛ إذ يحتاج الأطباء إلى فهم الأسباب الكامنة وراء تشخيص الخوارزميات؛ من أجل اتخاذ قرار مستنير بشأن خطة العلاج؛ وهو ما يتطلب وجود جيل جديد من الأطباء المهندسين الذين تخصصوا في الطب، وكذلك درسوا بعمق الإحصاء وما وراء هذه الخوارزميات.
2- الخصوصية: كما تُعد حماية خصوصية البيانات الطبية للمرضى أحد أكبر التحديات في استخدام الذكاء الاصطناعي في مجال الصحة؛ إذ يعتمد الذكاء الاصطناعي على كميات هائلة من البيانات لتحليل الأنماط، والتنبؤات، واتخاذ القرارات التي يمكن أن تحسن التشخيص والعلاج. ومع ذلك، تتضمن هذه البيانات غالباً معلومات حساسة تتعلق بصحة الأفراد وتاريخهم الطبي.
ولتفادي تعرض المرضى للأخطار الرقمية؛ يجب ضمان حماية البيانات من الاختراقات والهجمات السيبرانية. ولضمان الخصوصية؛ يجب إخفاء هوية البيانات الشخصية المستخدمة في مرحلة تعلم نماذج الذكاء الاصطناعي؛ يتطلب ذلك تقنيات متقدمة لضمان عدم إمكانية إعادة تحديد هوية الأفراد من خلال البيانات المجهولة. كما ينبغي أن يكون المرضى على دراية بكيفية استخدام بياناتهم وأن يعطوا موافقتهم الصريحة على ذلك. يتطلب ذلك الشفافية من قبل المؤسسات الطبية حيال كيفية جمع البيانات والأغراض من استخدامها ووسائل حمايتها.
3- صعوبة الوصول للبيانات: التحدي الآخر هو أن أنظمة الذكاء الاصطناعي والتعلم الآلي تتطلب كمية كبيرة من البيانات لتكون فعالة؛ وهو ما يمكن أن يكون مشكلة في مجال الرعاية الصحية؛ إذ إنه في الغالب يأتي المريض دون سجل مرضي سابق؛ مما يصعب الوصول إلى بيانات زمنية عن حالته الصحية، وكذلك أرشيف الأمراض في عائلته، وإن توفرت البيانات فإنها تكون في صيغ غير مقروءة آلياً وغير مهيكلة؛ مما يصعب من إمكانية التعامل معها رقمياً.
4- اختيار مؤشرات قياس الدقة: في عالم الذكاء الاصطناعي، تُعد دقة النموذج واحدة من أهم المقاييس لتقييم أداء نماذج التصنيف. تُعرف الدقة على أنها نسبة التنبؤات الصحيحة إلى إجمالي التنبؤات التي يُصدرها النموذج. قد تبدو دقة النموذج مؤشراً كافياً للحكم على فعالية النموذج، ولكن الاعتماد عليها بمفردها قد يكون مضللاً في الكثير من الحالات.
لنفترض أن لدينا نموذجاً يستخدم لتصنيف حالة الأشخاص بناءً على نتائج تحليل مخبري، في اختبار يضم 100 شخص خضعوا جميعاً لنفس الفحص، قد نجد أن النموذج قد صنّف 90 شخصاً بشكل صحيح بينما أخطأ في تصنيف 10 أشخاص. بناءً على هذه النتائج؛ يمكننا القول إن دقة النموذج هي 90%. هذا يبدو جيداً، وقد يشجع المتخصصين للتوصية بتعميم هذه التقنية؛ نظراً لما حققته من مستوى دقة يُعد مرتفعاً نسبياً.
ولكن ماذا لو كانت تفاصيل البيانات هي كالتالي: من بين 100 شخص، 89 منها سلبية (من دون مرض) و11 إيجابية (مع مرض) وقام النموذج بتصنيف جميع العينات الـ89 السلبية بشكل صحيح، لكنه أخطأ في تصنيف 10 من العينات الإيجابية على أنها سلبية، وصنّف واحدة فقط بشكل صحيح.
في هذا السيناريو، رغم أن الدقة لا تزال تبدو مرتفعة عند 90%، فإن النموذج في الواقع فشل في اكتشاف معظم الحالات المصابة. من بين 11 حالة إيجابية (مع مرض)، تم تصنيف واحدة فقط بشكل صحيح (مع مرض)، في حين أن 10 أشخاص تم تصنيفهم بشكل خاطئ. هذا يُظهر ضعفاً كبيراً في قدرة النموذج على التعرف على الحالات المصابة بالمرض؛ ما يعني أنه رغم ارتفاع نسبة الدقة؛ فإنه لا يمكن أن يكون مناسباً لتعميمه واستخدامه في اكتشاف المصابين بهذا المرض.
يوضح المثال السابق أنه لا يمكن الاعتماد فقط على دقة النموذج لتقييم أدائه بشكل كامل. هناك مقاييس أخرى تؤدي دوراً مهماً مثل: الحساسية sensitivity التي تُعنى بقدرة النموذج على اكتشاف الحالات الإيجابية، والدقة الإيجابية precision التي تُعنى بمدى صحة التنبؤات الإيجابية للنموذج.
الحساسية على سبيل المثال، تُظهر نسبة الحالات الإيجابية التي يتم تصنيفها بشكل صحيح. في مثالنا، الحساسية كانت منخفضة جداً؛ لأن النموذج أخفق في اكتشاف معظم الحالات الإيجابية؛ هذا يعني أنه في التطبيق العملي، قد يُعد النموذج غير مفيد رغم دقته العالية نسبياً.
5- انحياز النتائج بسبب التفاوت في بيانات التعلم: في مجال الذكاء الاصطناعي والتعلم الآلي، تُعد جودة وتوازن البيانات المستخدمة في تدريب النماذج أمراً حاسماً للحصول على نتائج دقيقة وموثوقة. عندما تكون البيانات غير متوازنة؛ أي أن هناك تفاوتاً كبيراً بين عدد المدخلات في الفئات المختلفة؛ فإن ذلك يمكن أن يؤدي إلى انحياز في نتائج النموذج. سنستعرض هنا مثالاً في المجال الطبي لتوضيح هذه النقطة، وكيف أن معالجة الخلل بتكرار بيانات الفئة الأقل لا تُعد حلاً عملياً.
لنفترض أننا نبني نموذجاً لتشخيص مرض نادر، ولدينا مجموعة بيانات تحتوي على 1000 سجل طبي، لكن فقط 50 من هذه السجلات تشير إلى المرض النادر (الفئة الإيجابية)، في حين أن 950 سجلاً تشير إلى عدم وجود المرض (الفئة السلبية).
في هذا السيناريو، هناك تفاوت كبير بين عدد السجلات في الفئات المختلفة. إذا قمنا بتدريب النموذج على هذه البيانات، فمن المرجح أن يتعلم النموذج تصنيف معظم الحالات على أنها سلبية ببساطة لأنه يرى عدداً أكبر بكثير من هذه الحالات. على سبيل المثال، يمكن للنموذج أن يتجاهل تقريباً الحالات الإيجابية ويحصل على دقة عالية جداً؛ لأنه صحيح في معظم الأحيان ببساطة؛ بسبب كثرة الحالات السلبية.
لحل هذه المشكلة رقمياً، يمكن لعلماء البيانات تكرار بيانات الفئة الأقل (الحالات الإيجابية لزيادة تمثيلها في مجموعة التدريب). على سبيل المثال، يمكننا تكرار السجلات الإيجابية 19 مرة بحيث يصبح لدينا 950 سجلاً إيجابياً لموازنة العدد مع السجلات السلبية.
رغم أن هذه الطريقة توازن العدد بين الفئات؛ فإنها لا تعكس تعدد الحالات. إذا كانت السجلات الأصلية تحتوي على 50 حالة إيجابية فقط؛ فإن تكرارها لا يضيف معلومات جديدة إلى النموذج. بدلاً من ذلك، يمكن أن يؤدي هذا إلى نموذج يتعلم التكرار المحدود بدلاً من تعميم الأنماط التي يمكن أن تتنوع في الواقع.
انحياز نتائج نماذج الذكاء الاصطناعي بسبب البيانات غير المتوازنة يمثل تحدياً كبيراً، خاصة في المجالات الحساسة مثل الرعاية الصحية، ومعالجة هذا التحدي تتطلب حلولاً تتجاوز التكرار البسيط للبيانات لضمان أن النموذج يتعلم من تنوع الحالات ويعكس الواقع بشكل أكثر دقة وفعالية. فاستخدام تقنيات متقدمة لجمع البيانات ومعالجتها؛ يمكن أن يؤدي إلى نماذج أكثر توازناً وموثوقية في الأداء.
ختاماً، يُحدث الذكاء الاصطناعي تحولاً كبيراً في مجال الرعاية الصحية؛ إذ يسهم في تحسين دقة التشخيص والعلاج، وتسريع عملية اتخاذ القرارات الطبية، وتطوير الأدوية بشكل أسرع وأكثر فعالية. وتقدم تقنيات الذكاء الاصطناعي والبيانات الضخمة فوائد عديدة مثل: تحسين دقة التشخيص، وتقليل التكاليف، وتخصيص خطط العلاج؛ مما يؤدي إلى تحسين جودة الرعاية الصحية بشكل عام. ومع ذلك، ما زالت هذه التقنيات تواجه تحديات كبيرة تتعلق بحماية الخصوصية، وانحياز البيانات، وتعقيد فهم نتائج الذكاء الاصطناعي. ويتطلب التغلب على هذه التحديات التزاماً بالابتكار المستمر والتعاون بين المهنيين الطبيين والخبراء في مجال الذكاء الاصطناعي لضمان تقديم أفضل رعاية ممكنة للمرضى.