
تُعرَّف البيانات الضخمة في العديد من المصادر بأنها كمية هائلة من البيانات التي يصعب تخزينها ومعالجتها بواسطة البرامج التقليدية بسبب تعقيدها. لكن هذا التعريف لا يعكس على نحو صحيح جوهر البيانات الضخمة. فحجم البيانات ليس هو العامل الوحيد الذي يجعلها "ضخمة"، فمنذ القدم، كان البشر يجمعون البيانات، لكنها لم تكن "ضخمة" بمعنى الكلمة إلا مع بزوغ عصر الرقمنة في مطلع القرن الحالي.
ومع انتشار الإنترنت ومواقع التواصل الاجتماعي وأجهزة الاستشعار، أصبحنا ننتج كميات هائلة من البيانات بشكل يومي. هذه البيانات متنوعة جداً، وتتراوح بين النصوص إلى الصور ومقاطع الفيديو، وتأتي من مصادر متعددة، مثل: مواقع التواصل الاجتماعي، المستشعرات، وحتى أجهزة إنترنت الأشياء.
ما يجعل هذه البيانات "ضخمة" هو قيمتها، وما يمكن أن يولد خلالها من معرفة. فهي ليست مجرد بيانات كمية أو وصفية، بل هي نافذة على العالم من حولنا. فإلى جانب التدفق الهائل يأتي تنوع المصادر وتكاملها؛ مما يشكل صورة واضحة حال تحليلها تساعد على صناعة قرارات مستنيرة، تمكن من فهم سلوك البشر، وتحسين الخدمات، وتطوير تقنيات جديدة.
أما الحجم فهو أحد خصائص البيانات الضخمة لكنه ليس السمة الوحيدة؛ إذ هناك ما يعرف بـ The 7 V’s of Big Data وهي السمات السبع للبيانات الضخمة، وهي: الحجم (Volume)، سرعة التدفق (Velocity)، التنوع (Variety)، الصدق (Veracity)، القيمة (Value)، التغير (Variability)، التمثيل البصري (Visualization). كما هو موضح في الشكل التالي:
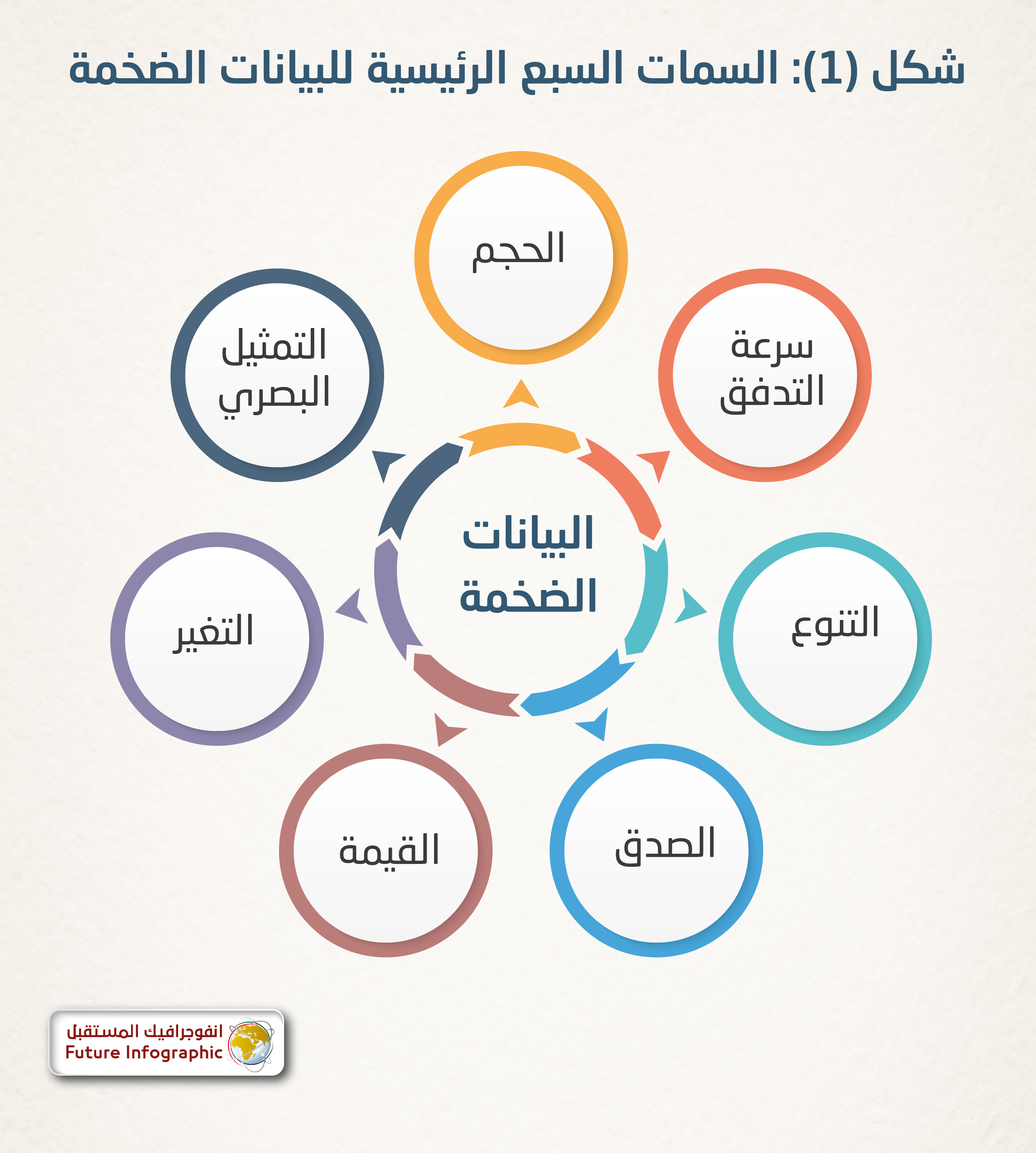
مصادر رقمية متعددة:
بدأت رحلة البيانات الضخمة في الظهور مع بداية عصر الحاسوب؛ إذ تمكنت الشركات من جمع وتخزين كميات كبيرة من البيانات، ولكن تحليلها كان صعباً؛ بسبب محدودية القدرات الحاسوبية. في الثمانينيات والتسعينيات، شهدت بعض المجالات، مثل التجارة الإلكترونية، نمواً سريعاً في كميات البيانات؛ ما أدى إلى ظهور بعض التقنيات الأولية لمعالجة البيانات الضخمة.
ومع بداية القرن الحادي والعشرين، شهد العالم ثورة رقمية حقيقية؛ إذ انتشر الإنترنت بشكل واسع أدى إلى وصوله لأغلب سكان الكوكب، تبعه ظهور مواقع التواصل الاجتماعي التي أصبحت منصات رئيسية لتبادل المعلومات؛ إذ أسهمت في تمكين المواطنين في شتى بقاع العالم من توثيق ونشر يومياتهم؛ مما عزز توليد تيارات هائلة من البيانات غير المنظمة، تتنوع ما بين نصوص وصور ومقاطع فيديو، بالتوازي مع تدفق هذا الكم الهائل من البيانات بحرية وسهولة أخذت المستشعرات، أو ما يعرف بإنترنت الأشياء (IOT) في الانتشار في مجالات عديدة مثل: الصحة والتعليم والأمن وغيرها؛ لتضيف على هذا الكم من البيانات تدفقاً آخر؛ وقد أدى ذلك إلى توليد كميات هائلة من البيانات تميزت بتنوعها وثرائها، فجاءت عبر قطاعات عدة وبتنسيقات عدة.
أدت هذه التطورات إلى زيادة هائلة في كميات البيانات التي يتم إنشاؤها؛ مما أدى إلى ظهور مصطلح البيانات الضخمة.
وقد عزز نهج التحول الرقمي الذي انتهجته الكثير من المؤسسات والحكومات حول العالم؛ تحويل البيانات من النسخ الورقية إلى نسخ رقمية يمكن تخزينها ومعالجتها وربطها ببعضها عبر قواعد بيانات منظمة ومتشابكة للحصول على صورة متكاملة؛ ومن ثم قرارات مستنيرة. على سبيل المثال، تُستخدم تطبيقات الهاتف المحمول في جمع البيانات الصحية من المرضى؛ مما يُساعد الأطباء على تشخيص الأمراض بشكل أكثر دقة وتقديم العلاج المناسب. كما تُستخدم أنظمة إدارة الموارد البشرية في جمع البيانات عن الموظفين، مما يُساعد الشركات على تحسين كفاءة العمليات وتقديم حوافز أفضل للموظفين.
أدوار استشرافية وتنبؤية:
يُعد تحليل البيانات لاستخلاص المعرفة أحد أهم التطبيقات العملية للبيانات الضخمة. فباستخدام تقنيات التحليل الإحصائي والرياضياتية المتقدمة، يمكن استخراج أنماط واتجاهات وتوقعات من هذه البيانات الهائلة؛ ومن خلال فهم هذه الأنماط؛ يمكن اتخاذ قرارات استراتيجية تؤثر بشكل كبير في عمل المؤسسات.
وتنقسم طرق التحليل إلى أربع فئات رئيسية حسب درجة التعقيد: التحليل الوصفي والتحليل التشخيصي والتنبؤي والتوجيهي، وكلما انتقلت من الأبسط إلى الأكثر تعقيداً، تزداد الصعوبة والموارد المطلوبة، وكذلك مستوى المعطيات الناتجة عن عملية التحليل.
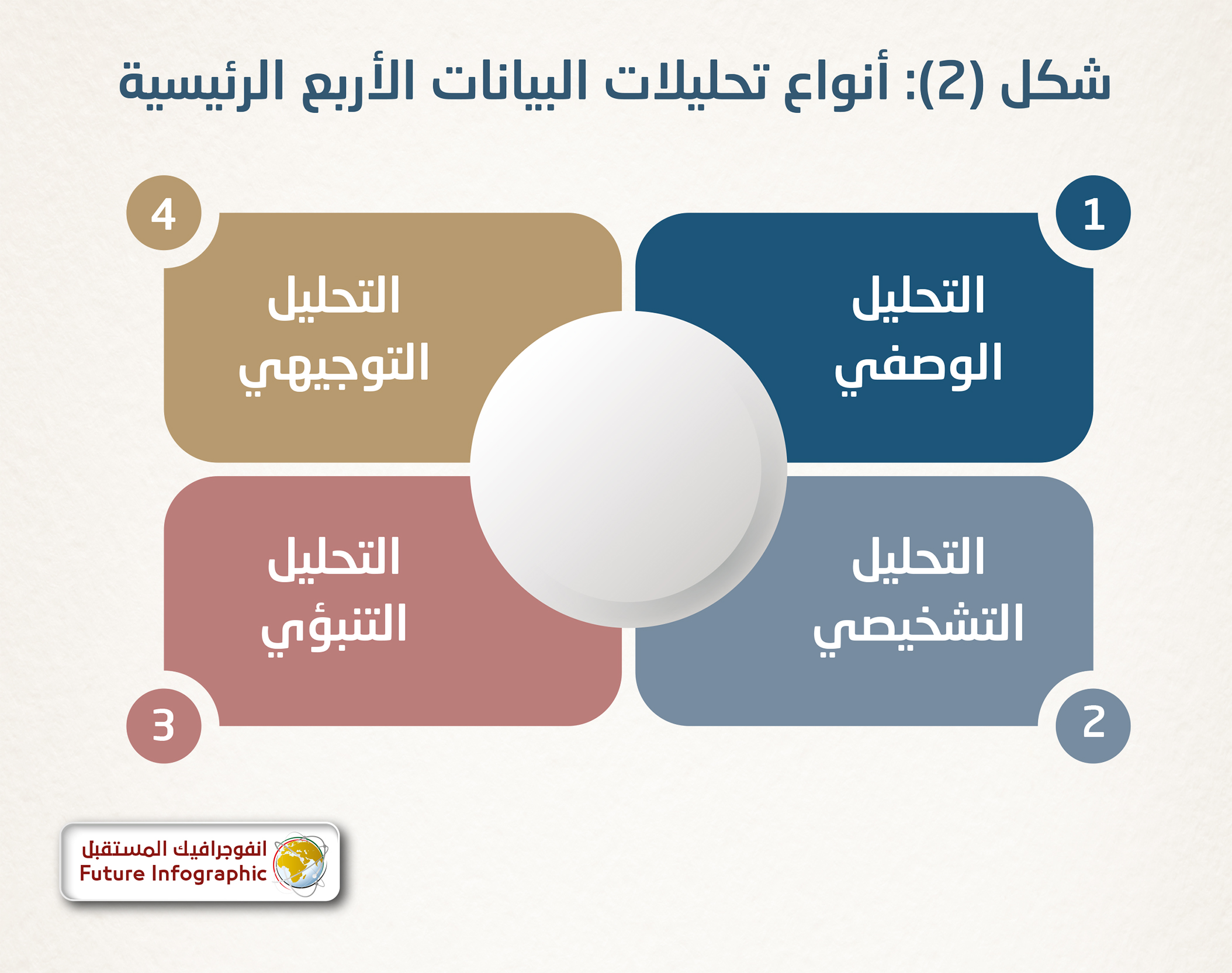
1- التحليل الوصفي: هو الخطوة الأولى والأكثر شيوعاً والأبسط في إجراء أية عملية تحليل إحصائي، والغرض منه هو الإجابة عن سؤال، ماذا حدث؟ بمعنى آخر، فإنه يعطي وصفاً لما حدث في الماضي، ويتم ذلك عن طريق تلخيص البيانات السابقة وبناء وتفسير البيانات الأولية من مصادر مختلفة لتحويلها إلى رؤى قيمة.
2- التحليل التشخيصي: الذي يشار إليه غالباً باسم تحليل السبب الجذري، فهو نوع متقدم من التحليل يتقدم خطوة أخرى إلى البيانات أو المحتوى للإجابة عن سؤال لماذا حدث هذا؟ فيما يتميز التحليل التشخيصي بأساليب مثل: التنقيب عن البيانات والارتباط، ويلقي نظرة أعمق على البيانات لفهم أسباب الأحداث والسلوكيات؛ مما يسمح بفهم المعلومات بسرعة أكبر.
3- التحليل التنبؤي: فهو يحدد النتائج المحتملة من خلال تحديد الميول في التحليلات التشخيصية والوصفية. ويأخذ البيانات السابقة ويغذيها في نموذج التعلم الآلي الذي يأخذ في الاعتبار الأنماط الرئيسية. ثم يتم تطبيق النموذج على البيانات الحالية للتنبؤ بما سيحدث؛ ما يسمح باتخاذ إجراءات وقائية. ومن أكثر أشكال هذا النوع من التحليلات شيوعاً هو تحليل السلاسل الزمنية لدراسة الأنماط في حركة البيانات خلال الزمن ومعرفة إذا كان هناك تأثير لموسم وحدث معين في حركة البيانات دائم التكرار يمكن فهم خواصه وتأثيره؛ ومن ثم التنبؤ بأثره مستقبلاً بناءً على التحليلات التاريخية التي تمت لفترات سابقة.
4- التحليل التوجيهي: يُعد بمثابة عملية تحليل للبيانات إلى جانب تقديم نصائح فورية حول كيفية تحسين ممارسات العمل لتناسب العديد من النتائج المتوقعة في الواقع، فهو "يأخذ ما نعرفه البيانات، ويفهم البيانات للتنبؤ بما يحدث، ويقترح أفضل الخطوات التطلعية بناءً على المحاكاة الواعية، ويحدد العواقب المحتملة لكل منها". والغرض من التحليل التوجيهي -وهو بالتأكيد المجموعة الأكثر تقدماً في قائمتنا- هو اقتراح طريقة عملية لتجنب المشكلات المستقبلية أو لتحقيق أقصى استفادة من عملية واعدة.
إلى ذلك، يمكن للحكومات والمؤسسات الاستفادة من البيانات الضخمة بشكل كبير؛ لتحسين الخدمات العامة وصنع السياسات الفعالة، وذلك كما يتضح من الشكل التالي:

تطوير الذكاء الاصطناعي:
أدت البيانات الضخمة دوراً محورياً في تطور الذكاء الاصطناعي. فقد أصبحت البيانات الوفيرة والمتنوعة غذاءً للنماذج التي تعتمد عليها تقنيات الذكاء الاصطناعي، مثل التعلم العميق، وتعتمد هذه النماذج على تحليل كميات هائلة من البيانات لاكتشاف الأنماط واستخراج المعرفة؛ مما يؤدي إلى تحسين أداء الأنظمة الذكية في مختلف المجالات.
البيانات الوفيرة والمتنوعة تُعد غذاءً للنماذج التي يعتمد عليها الذكاء الاصطناعي. على سبيل المثال، تُستخدم بيانات النصوص والصور والفيديوهات لتدريب نماذج التعلم العميق؛ مما يمكنها من التعرف على الأشياء، وفهم اللغة الطبيعية، واتخاذ القرارات المعقدة. فمن دون هذه البيانات، سيكون من الصعب تحقيق التقدم الذي نشهده اليوم في مجالات مثل: التعرف على الصوت والصورة، والترجمة الآلية، وتحليل البيانات.
لقد ساعدت البيانات الضخمة علماء البيانات على تطوير نماذج تعلم الآلة بشكل ملحوظ. فبفضل توفر كميات ضخمة من البيانات، يمكن للباحثين تطوير نماذج أكثر دقة وفعالية. فالبيانات الوفيرة والمتنوعة تعزز تقدم دقة نماذج الذكاء الاصطناعي، وتسهم في ظهور تقنيات جديدة. على سبيل المثال، يعتمد التعلم العميق، وهو فرع من فروع تعلم الآلة، على شبكات عصبية صناعية تحاكي الطريقة التي يعمل بها دماغ الإنسان، وتحتاج هذه الشبكات إلى كميات ضخمة من البيانات لتدريبها.
علاوة على ذلك، فإن البيانات الضخمة تمكن الذكاء الاصطناعي من التكيف مع التغيرات المستمرة في البيئة والتعلم منها. ففي مجالات مثل الرعاية الصحية، يمكن استخدام البيانات الضخمة لتحليل السجلات الطبية وتحديد الأنماط التي تساعد على تشخيص الأمراض وتطوير خطط علاجية مخصصة، وفي الصناعة، تُمكِّن البيانات الضخمة من تحسين عمليات الإنتاج من خلال تحليل بيانات الأداء واكتشاف الفرص لتحسين الكفاءة والجودة.
ولكن مع كل هذه الفوائد، تأتي تحديات كبيرة؛ إذ يتطلب التعامل مع كميات ضخمة من البيانات بنية تحتية قوية للتخزين والمعالجة، بالإضافة إلى تقنيات متقدمة للحفاظ على أمن البيانات وخصوصيتها. كما أن جودة البيانات تؤدي دوراً حاسماً في فعالية نماذج الذكاء الاصطناعي؛ إذ إن البيانات غير النظيفة أو المتحيزة يمكن أن تؤدي إلى نتائج غير دقيقة أو مضللة.
تحديات الأمن والخصوصية:
تواجه صناعة البيانات الضخمة العديد من التحديات والمخاطر؛ إذ يُعد أمن وخصوصية البيانات أحد أهم هذه التحديات. فمع زيادة حجم البيانات وتنوعها، يصعب حفظها وحمايتها من الاختراقات والاستخدامات غير المصرح بها؛ مما يهدد خصوصية المستخدمين ويضعهم في موقف معرض للخطر. لذلك، يجب تطوير سياسات وأنظمة أمنية متقدمة لحماية البيانات الضخمة وضمان سلامتها من الاختراقات والاستغلال غير المشروع.
1- التحديات الأمنية:
تُعد مراكز البيانات التي تخزن البيانات الضخمة هدفاً رئيسياً للهجمات الإلكترونية، ويمكن أن يؤدي اختراق هذه المراكز إلى سرقة البيانات أو تعطيل الخدمات، بالإضافة إلى ذلك، يمكن للقراصنة استهداف أنظمة تخزين البيانات وسرقة المعلومات الحساسة مثل: البيانات الشخصية أو المالية. تهديد آخر يأتي من الداخل؛ إذ قد يكون الموظفون أو المتعاقدون مصدراً للتهديدات الأمنية؛ إذا تمكنوا من الوصول إلى البيانات الحساسة بشكل غير قانوني. وأخيراً، يمكن أن يتسبب القراصنة في إلحاق الضرر بالبيانات أو تعطيل الخدمات بشكل متعمد بهدف التخريب.
2- تحديات الخصوصية:
من ناحية الخصوصية، يُعد استخدام البيانات دون موافقة صاحبها تحدياً كبيراً. فقد يتم بيع البيانات الشخصية إلى شركات تسويق أو استخدامها لأغراض غير قانونية. بالإضافة إلى ذلك، قد تُستخدم البيانات الضخمة لتعقب الأفراد أو مراقبة سلوكهم دون علمهم؛ مما يشكل انتهاكاً للخصوصية. وتبرز مشكلة التحيز في البيانات، إذ يمكن أن تُستخدم البيانات الضخمة لتأكيد التحيزات الموجودة في المجتمع؛ مما يؤدي إلى التمييز ضد بعض الفئات.
3- مواجهة التحديات:
لمواجهة هذه التحديات، يمكن اتخاذ عدة إجراءات، ويُعد التشفير من أهم الوسائل لحماية البيانات الضخمة؛ إذ يتم تحويل البيانات إلى شكل غير قابل للقراءة إلا بواسطة الأشخاص المصرح لهم. كذلك، يجب مراقبة الوصول إلى البيانات بدقة، بحيث يتم منح الوصول فقط للأشخاص المصرح لهم. يتطلب الأمر أيضاً استخدام تقنيات أمنية متطورة لحماية البيانات من الهجمات الإلكترونية، مثل: جدران الحماية ونظم الكشف عن الاختراقات. وتُعد التوعية بأهمية الأمن والخصوصية ضرورية؛ إذ يجب تعليم الموظفين والمستخدمين كيفية حماية البيانات من المخاطر.
وعلى صعيد السياسات، يجب وضع لوائح واضحة تحكم استخدام البيانات الضخمة وتضمن احترام خصوصية الأفراد. كما أن التعاون بين الحكومات والشركات والمؤسسات البحثية يُعد ضرورياً لتطوير حلول مشتركة لمواجهة تحديات الأمن والخصوصية في عصر البيانات الضخمة.
في النهاية، باتت البيانات الضخمة بمثابة "نفط القرن" باعتبارها تمثل كنزاً كبيراً لكل من يمتلكها ولديه القدرة على تحليلها والاستفادة منها، في عصر باتت فيه البيانات أكثر أهمية من السلاح؛ لأنها قد تتوقف عليها مصائر دول.